

By Jesper Buus Nielsen, Professor and Chief Cryptographic System Designer, Partisia
In this post I will describe how the Partisia Blockchain infrastructure for MPC-as-a-Service works. I assume the reader is familiar with earlier posts in the series on Blockchain and MPC.
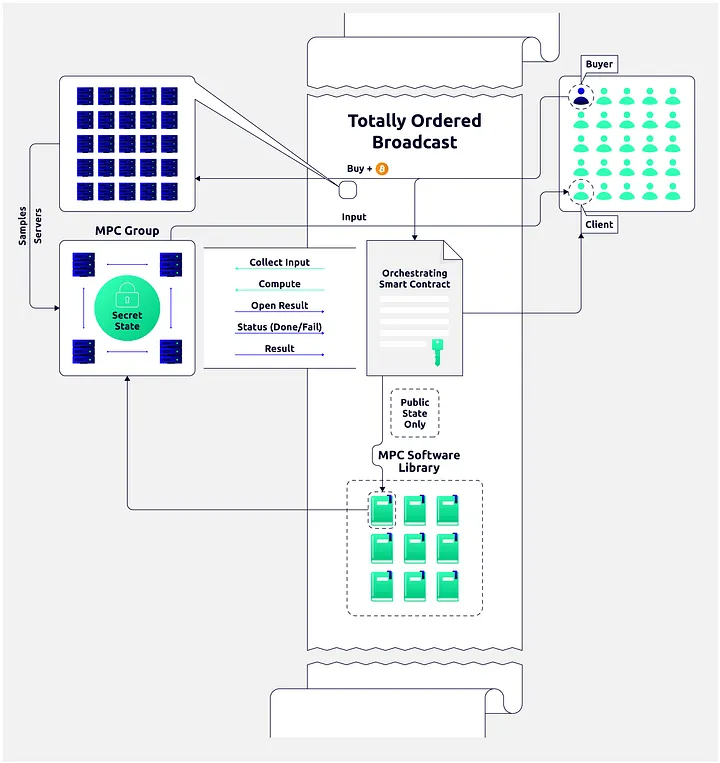
The purpose of the infrastructure is to offer MPC-as-a-service. Service Buyers can rent servers and software to run an MPC. Clients can give secret input to the MPC. Computations can be performed on the secret inputs, and selected outputs can be made public. I first describe the individual actors in the infrastructure and then discuss how they interact to perform the show. In the end I then discuss briefly why the framework is designed as it is.
The Actors
The architecture is basically an event-driven architecture (EDA). Service Buyers, Clients and Smart Contracts create events on a totally-ordered broadcast channel. These events instruct off-chain MPC servers to perform certain MPC computations and report back the status.
The TOB
There is a BFT-based totally-ordered broadcast channel on which commands can be given and status codes recorded. I will call it the TOB for brevity. It acts like the event-channel in the EDA.
The TOB is a so-called pipelined-BFT as discussed in for instance “PaLa”. There is a sequencer and a committee of validators. The sequencer can propose new blocks. New blocks have to point to a previously notarised block. Validators will sign off on a block if it points to the newest notarised block that they know. When two thirds of the committee signed off on a block it is considered notarised. If a block is notarised and is pointed to by a newer notarised block it is considered final. The contents of the TOB are the events in the unique sequence of final blocks. This allows to create finalised blocks in a streaming manner and with a delay of one network round trip. There is a fallback mode based on Byzantine Agreement to handle deadlocks resulting from the sequences being corrupted. We will describe the TOB in more detail in a later post.
The TOB is partially synchronous. This just means that if you post to it, then your message is guaranteed to arrive within some finite upper bound U. However, this U might depend on the network conditions and is unknown to the user of the TOB. This basically just means that if you post a message then you know that it will eventually arrive, but you have no guarantee about how fast. The reason for this choice is that it is notoriously hard to give quality-of-service guarantees for open blockchains which hold even under worst case network conditions and when under attack. And we do not want the security of the MPC computations to fail because of a missed timeout which was set in naivety. We therefore assume we know nothing about the delivery time except that it is finite.
The TOB holds a totally ordered sequence of events. The TOB also holds accounts. Each account has a number of utility tokens called MPCs. These MPCs are used for staking MPC Nodes. If an MPC Node is seen cheating in an MPC Service its stake can be taken. The stake can also be used as security if the MPC Service is handling values, like moving cryptocurrencies to and from other blockchains.
The MPC Node Pool
There is an MPC Node Pool. It consists of MPC Nodes. Each MPC Node is an identified, vetted and staked machine willing to participate as a server in MPC-as-a-service. The MPC Nodes have some publicly available properties like which legal entity made the machine available, which country it is in, what process was used to vet the machine, et cetera. This is among other things to be able to use diverse MPC nodes in a given MPC computation.
MPC Groups
Each MPC Service is being run by a small MPC Group, which is just a random subset of the total MPC Node Pool. The MPC Nodes in the MPC Group know each other and agree on which service they run. The MPC Groups are the event processing engines of the EDA. They do not do anything on their own. They only react to events on the TOB.
MPC Services
An MPC Service is just a particular program run using MPC by a particular MPC Group.
Secret Variables
The secret state of an MPC Service is not kept on the TOB. It is held by an MPC Group off-chain. The MPC Group will use secret sharing to hold a set of Secret Variables which make up the secret state of the service. More Secret Variables can be computed along the way, when inputs are given or computations are performed on existing Secret Variables. Secret Variables might also be opened to reveal outputs from the service. They can be open unto the TOB or to an individual Client depending on whether the output is public or private.
Service Buyers and Clients
Service Buyers and Clients are the entities using an MPC Service. They are event generators of the EDA. The Service Buyer can use the TOB to pay an MPC Group to run a given service for it. The Clients can use the TOB to provide inputs to an MPC Service run by an MPC Group.
MPC Smart Contracts
There are special MPC Smart Contracts on the TOB which allow to describe and orchestrate the control flow of an MPC Service. These are also event generators of the EDA. The smart contract can put algorithmically generated events on the TOB. We think of these events as issuing commands to the MPC Group. In practice it is the MPC group which observes the TOB and reacts when the events are put on the TOB.
The Show
I now dive into how the actors interact in the show. We look at the flow of an MPC Service from birth until outputs start being given.
Buying a Service
A Service Buyer will post a Buy event to the TOB indicating that an MPC Service is being bought. It specifies what program the service should run, how many MPC Nodes should run the MPC, their types, et cetera. It will also pay for setting up the service.
On the PBC platform Service Buyers can pay for services using cryptocurrencies from other blockchains, making PBC a bring-your-own currency (BYoC) platform. Results of MPC services can also be delivered back to other blockchains. This allows PBC to provide MPC-as-a-Service as a Layer 2 on top of existing blockchains, or MPC-as-a-Service-as-a-Service if you will.
Scrambling the MPC Nodes
Once the Buy event appears on the TOB a protocol is run which samples a random set of MPC Nodes with the needed properties and size, this is the MPC Group for the MPC Service. The MPC Group is made aware of each other and how to contact each other via an event on the TOB.
Fuelling
Once the MPC Group has been scrambled it starts generating preprocessing material which will allow the MPC Group to do the actual computation in an asynchronous manner [see Beaver’s trick]. It is reported on the TOB how much material has been generated and the computation can begin when enough has been generated. More preprocessing can be generated in parallel with the on-going computation and we have therefore chosen to call it fuelling. PBC uses a particular way to do this where the fuelling can be generated by a Fuelling Group, which is a larger group of MPC Nodes including the MPC Group running the MPC Service. This can be done such that the MPC Group is minimally involved in the Fuelling. This offloads preprocessing work from the MPC Group which will be plenty busy running the MPC Service.
Input
When a client gives input it holds a secret input value V. It wants V to end up in a Secret Variable held by the MPC Group of the MPC Service. There are several ways to do this.
A fairly straightforward solution is to have the client generate a representation of the secret variable and send the share for each MPC Node in the MPC Group via a secure channel. Extra measures need to be applied to deal with a malicious client sending an inconsistent representation which might corrupt the MPC service. This is explored in more detail in for instance this paper “A Framework for Outsourcing of Secure Computation”.
A practical obstacle with the above approach is that the Client has to contact several MPC Nodes and be aware of how to do this. And MPC Nodes need to open up for being contacted directly by clients, which is not optimal from a security point of view. A more practical approach is to encrypt the share for each MPC Node under its public key and leave the ciphertext on the TOB. However, this allows a bad actor to collect the ciphertext and decrypt it at some future point in time when computers get faster. One should therefore avoid putting encrypted sensitive values on a blockchain if at all possible.
A more appealing approach is for the MPC Nodes to each send a message to the Client which opens up a Secret Variable containing a random value R. This value R should be unknown to all MPC Nodes. Each MPC Node will encrypt its share of R under the public key of the Client. Only the client will see all shares and be able to compute R. The ciphertexts can be signed by the MPC Servers and be sent as a single message via a proxy such that the Client receives a single message from the PBC platform. The Client will then post D=(V — R) on the TOB. This is secure as subtracting the random R acts as a one-time pad encryption which cannot be broken even with unbounded computing power. From the TOB the MPC group can learn D=(V — R) and add this value to the Secret Variable containing R. This gives a new Secret Variable containing V, as desired.
Secret Computation
Secret Computations can be performed on the Secret Variables held by a given MPC Service. The MPC Group never initiates this on their own. Secret Computations are always triggered by events on the TOB. For instance the arrival of enough inputs on the TOB might trigger the MPC Group to compute the result of an auction. It can also be that the block time in the newest block on the TOB implies that a timeout has been met and now a computation is done on the available inputs and secret state. It may also happen that a particular event is posted on the TOB by a coordinator instructing that a particular computation should now begin. Several Secret Computations can be run in parallel.
When a Secret Computation is done the MPC Nodes report this back on the TOB. When enough MPC Nodes report that the Secret Computation is done, this is considered a Done event on the TOB. This might in turn trigger new Secret Computations. A timeout can be set for a Secret Computation. If the Done event does not arrive before the timeout, the Secret Computation is considered as failed and will be dropped: no Secret Variables are created and the old ones are left as they were.
Importantly, the Secret Computation event only triggers that new Secret Variables be created. It never opens up Secret Variables. Therefore a Secret Computation does not leak any information. One implication of this is that if a Secret Computation fails it can simply be ignored: no information leaked and any newly created Secret Variable can be dropped. Then it is as if the failed Secret Computation never happened.
A failed Secret Computation might trigger new Secret Computations to be called, for instance a recomputation with a longer timeout and/or using a more robust protocol for the Secret Computation. This gives a simple way to handle unfortunate network conditions making some sub-computation fail. If a Secret Computation fails due to for instance a dropped connection between two MPC Nodes, then we simply rerun that section of the computation.
Another application of the ability to ignore failed Secret Computations is that in optimistic mode the Secret Computations can be formed with fast protocols which might deadlock in the face of cheating in the protocols. And then only when actual cheating takes place do we use slower and more robust protocols.
Output
Once the desired results of the MPC Service have been stored in Secret Variables, these can be opened up to the Clients that should see them. This is done the same way as we gave the random R to the client during Input above. Should an Output fail, it can be repeated until successful. A failed Output is more problematic than a failed Secret Computation, as the failed attempt might have revealed the secret output to some parties but not others. Learning an output earlier than others might give an advantage. Learning it exclusively could also be a huge advantage. The PBC platform therefore allows specialised output protocols involving more servers than during Secret Computations to ensure increased robustness when giving output. First the secret variable is secret shared among more MPC Nodes, called the Fairness Group. Only when this is successful will the MPC Nodes attempt to reconstruct the output. The extra redundancy makes it more unlikely that enough MPC Nodes collude to make the output fail. We will not dive further into this here.
Ongoing Computations
MPC Services do not necessarily compute simple functions from input to output. Secret variables can be used to hold secret states over long periods, for instance representing a database of secret data from several data providers. Outputs can be given at several points in time, for instance weekly statistics over the dataset. New inputs can be given on a running basis, continuously extending the database. Which inputs to give next and which Secret Computations to do next might also depend on previous outputs and so on. This can all be pieces together using a sequence of Input, Secure Computation, and Output.
The exact control flow of what commands to run next, when to rerun, with what timeout, and with how robust a protocol et cetera can be programmed using a smart contract language on the TOB for describing and orchestrating MPCs, but we will not dive into this here.
Design Choices: Partial Synchrony
A main rationale behind the design described above is partial synchrony. We assume that all messages are eventually delivered, but we do not want to make any concrete assumptions on how long it takes. An example of this design pattern is the timeouts of the Secret Computations. It can be set to a reasonable ad hoc guess. If the Secret Computation fails due to a timeout, one can retry with a higher timeout and in general a larger guess at network delivery time. This allows us to adjust to changing network conditions. It also avoids resting security on a failed assumption on message delivery time.
Design for Honesty as a Default
Another main rationale behind the design is designing for honest operation as the default. By this we mean that we assume that in typical operation all MPC Nodes are honest. Only occasionally and exceptionally will MPC Nodes misbehave. This is a reasonable assumption in a semi-permission network with wetted and staked MPC Nodes. One can exploit this assumption by designing protocols which are fast when all parties are honest and which only revert to a slower mode when there are actual corruptions to handle. As an example, when using secret sharing-based MPC one can have an optimistic mode with just n=t+1 servers during Secret Computations. Here tis the maximal number of corrupted servers to tolerate without privacy breaking. This mode might deadlock, but will always be secure. If there was a deadlock we can then rerun with a pessimistic mode with n’=3t+1 active servers and a more robust protocol which is guaranteed to terminate. The totally ordered broadcast is designed according to the same Honesty as a Default principle, but this is a story for another post.
Epilogue
We have seen how preprocessing for MPC and an event-driven architecture can be used to create a partially synchronous MPC-as-a-Service platform. The computation unfolds solely via events on the partially synchronous totally-ordered broadcast channel. The MPC Group acts as a service provider to the totally-ordered broadcast channel. This event-based architecture allows a simple yet robust mode of execution. The platform is designed to be fast in normal operation and only revert to slower, pessimistic protocols when there are actual ongoing attacks.


